Prefix Sum
Last updated: Jul 28, 2026Table of Contents
- Overview
- Key Properties
- References
- Problem Categories
- Pattern 1: Basic Range Sum — LC 303
- Pattern 2: Subarray Sum Equals Target — LC 560
- Pattern 3: Subarray with Divisibility/Modulo — LC 523
- Pattern 4: Range Addition/Difference Array — LC 370
- Pattern 5: 2D Prefix Sum — LC 304
- Pattern 6: Transform and Count — LC 1248
- Pattern 7: Sum of Distances (Left-Right Split) — LC 2615
- Pattern 8: Prefix Maximum (Greedy Chunk / Partition) — LC 769
- 0) Concept
- How to Build the Prefix Sum Array (核心)
- Why sum(l, r) = prefix[r+1] - prefix[l]
- Concrete Example — LC 303
- Two Styles Comparison
- Templates & Algorithms
- Template Comparison Table
- Universal Template
- Template 1: Basic Prefix Sum (Range Queries) — LC 303
- Template 2: HashMap + Prefix Sum (Subarray Target Sum) — LC 560
- Template 3: Modulo Prefix Sum (Divisibility Problems) — LC 974
- Template 4: Difference Array (Range Updates) — LC 370
- Template 5: 2D Prefix Sum — LC 304
- Template 6: Transform and Count — LC 1248
- Template 7: Sum of Distances (Left-Right Split) — LC 2615
- Template 8: Prefix Maximum (Greedy Chunk / Partition) — LC 769
- Problems by Pattern
- Pattern-Based Problem Classification
- Additional Practice Problems
- Pattern Selection Strategy
- Decision Framework for Prefix Sum Problems
- Template Selection Guide
- Problem Identification Patterns
- Legacy Examples
- 1) LC Example
- 1-1) Flip String to Monotone Increasing — LC 926
- 1-2) Range Addition — LC 370
- 1-3) Count Number of Nice Subarrays — LC 1248
- 1-4) Maximum Size Subarray Sum Equals k — LC 325
- 1-5) Subarray Sum Equals K — LC 560
- 1-6) Continuous Subarray Sum — LC 523
- 1-7) Max Chunks To Make Sorted — LC 769
- 1-8) Maximum Sum of Two Non-Overlapping Subarrays — LC 1031
- 1-9) Maximum Side Length of a Square with Sum ≤ Threshold — LC 1292
- 1-10) Longest Well-Performing Interval — LC 1124
- 1-11) Sum of Distances — LC 2615
- Summary & Quick Reference
- Complexity Quick Reference
- Template Quick Reference
- Core Mathematical Insights
- Common Patterns & Tricks
- Problem-Solving Steps
- Common Mistakes & Tips
- Interview Tips
- Related Topics
- Advanced Extensions
Prefix Sum (前缀和)

Overview
Prefix Sum is a preprocessing technique that allows us to compute the sum of any subarray in O(1) time after O(n) preprocessing. The core idea is to precompute cumulative sums from the beginning of the array to each position.
Key Properties
- Time Complexity:
- Preprocessing: O(n)
- Query subarray sum: O(1)
- Overall: O(n) preprocessing + O(1) per query
- Space Complexity: O(n) for storing prefix sums
- Core Idea:
prefixSum[i] = nums[0] + nums[1] + ... + nums[i-1] - Subarray Sum:
sum(i, j) = prefixSum[j+1] - prefixSum[i] - When to Use:
- Multiple range sum queries
- Subarray problems with conditions
- Converting O(n²) to O(n) with HashMap
- 2D range sum queries
References
- Fucking Algorithm - Prefix Sum
- LeetCode Prefix Sum Problems
- LeetCode Problem Set Discussion
- Hash Map Cheatsheet
Problem Categories
Pattern 1: Basic Range Sum — LC 303
- Description: Calculate sum of elements in any given range [i, j]
- Examples: LC 303 - Range Sum Query, LC 304 - Range Sum Query 2D
- Pattern: Direct application of prefix sum formula
- Key Insight:
sum[i:j] = prefixSum[j+1] - prefixSum[i]
Pattern 2: Subarray Sum Equals Target — LC 560
- Description: Find/count subarrays with sum equal to target value
- Examples: LC 560 - Subarray Sum Equals K, LC 325 - Maximum Size Subarray Sum Equals k
- Pattern: Use HashMap to store prefix sums and check if
(current_sum - target)exists - Key Insight: If
prefixSum[j] - prefixSum[i] = k, thenprefixSum[i] = prefixSum[j] - k
Pattern 3: Subarray with Divisibility/Modulo — LC 523
- Description: Problems involving divisibility, remainders, or modulo operations
- Examples: LC 523 - Continuous Subarray Sum, LC 974 - Subarray Sums Divisible by K
- Pattern: Store remainders instead of actual sums in HashMap
- Key Insight: If
(prefixSum[j] - prefixSum[i]) % k = 0, thenprefixSum[j] % k = prefixSum[i] % k
Pattern 4: Range Addition/Difference Array — LC 370
- Description: Efficiently apply range updates to arrays
- Examples: LC 370 - Range Addition, LC 1094 - Car Pooling
- Pattern: Use difference array technique with prefix sum
- Key Insight: Add at start, subtract at end+1, then compute prefix sum
Pattern 5: 2D Prefix Sum — LC 304
- Description: Calculate sum of any rectangular region in 2D matrix
- Examples: LC 304 - Range Sum Query 2D, LC 1314 - Matrix Block Sum
- Pattern: Build 2D prefix sum matrix, use inclusion-exclusion principle
- Key Insight:
sum = total - left - top + topleft
Pattern 6: Transform and Count — LC 1248
- Description: Transform array elements and use prefix sum for counting
- Examples: LC 1248 - Count Nice Subarrays, LC 926 - Flip String to Monotone
- Pattern: Convert elements to 0/1, then apply prefix sum with conditions
- Key Insight: Transform problem to simpler prefix sum problem
Pattern 7: Sum of Distances (Left-Right Split) — LC 2615
- Description: Calculate sum of absolute differences between indices efficiently
- Examples: LC 2615 - Sum of Distances, LC 2121 - Intervals Between Identical Elements, LC 1685 - Sum of Absolute Differences
- Pattern: Split into left/right parts, use
count * value - sumformula - Key Insight: For index
i, distance =(i * countLeft - sumLeft) + (sumRight - i * countRight)
Pattern 8: Prefix Maximum (Greedy Chunk / Partition) — LC 769
- Description: Track the running maximum of the array. When
maxSoFar == i, the prefix[0..i]contains exactly the elements{0, 1, ..., i}and can form an independent sorted chunk. - Examples: LC 769 - Max Chunks To Make Sorted, LC 768 - Max Chunks To Make Sorted II
- Pattern: Single pass with a
maxSoFarvariable; increment chunk count whenevermaxSoFar == currentIndex - Key Insight: Because the array is a permutation of
[0, n-1], if the max value seen so far equals the current index, all values needed for positions0..iare already present inarr[0..i]
0) Concept
How to Build the Prefix Sum Array (核心)
The whole technique rests on one core line. Memorize this and the rest follows:
for i in range(len(cnt)):
prefix[i + 1] = prefix[i] + cnt[i]
Step-by-step:
cnt = [1, 0, 1, 1, 1]
# Step 1: allocate size n+1, fill with 0
# the leading prefix[0] = 0 is the "empty sum" sentinel
# -> lets sum(0, r) work without a special case
prefix = [0] * (len(cnt) + 1)
# prefix = [0, 0, 0, 0, 0, 0]
# Step 2: each prefix[i+1] = running total up to (and including) cnt[i]
for i in range(len(cnt)):
prefix[i + 1] = prefix[i] + cnt[i]
# prefix = [0, 1, 1, 2, 3, 4]
Trace (why the index is i + 1, not i):
cnt: [ 1, 0, 1, 1, 1 ]
index i: 0 1 2 3 4
prefix[0] = 0 ← sentinel (empty prefix)
prefix[1] = prefix[0] + cnt[0] = 0 + 1 = 1
prefix[2] = prefix[1] + cnt[1] = 1 + 0 = 1
prefix[3] = prefix[2] + cnt[2] = 1 + 1 = 2
prefix[4] = prefix[3] + cnt[3] = 2 + 1 = 3
prefix[5] = prefix[4] + cnt[4] = 3 + 1 = 4
prefix = [0, 1, 1, 2, 3, 4]
↑ ↑
empty sum sum of ALL cnt
Key:
prefixis one element LONGER thancnt.prefix[i+1]answers “sum of the firsti+1elements” =cnt[0] + ... + cnt[i].
One-liner alternative (itertools.accumulate with a leading 0):
from itertools import accumulate
prefix = list(accumulate(cnt, initial=0)) # [0, 1, 1, 2, 3, 4]
Why sum(l, r) = prefix[r+1] - prefix[l]
Given nums: [ a, b, c, d, e ]
Index: 0 1 2 3 4
Build prefix array (size n+1, prefix[0] = 0):
prefix[0] = 0
prefix[1] = a
prefix[2] = a + b
prefix[3] = a + b + c
prefix[4] = a + b + c + d
prefix[5] = a + b + c + d + e
Visual:
prefix: 0 | a | a+b | a+b+c | a+b+c+d | a+b+c+d+e |
index: 0 1 2 3 4 5
To get sum(l=1, r=3) = nums[1] + nums[2] + nums[3] = b + c + d:
prefix[r+1] = prefix[4] = a + b + c + d
prefix[l] = prefix[1] = a
─────────────
prefix[4] - prefix[1] = b + c + d ✓
Visually (what gets cancelled out):
prefix[4]: [ a | b | c | d ]
prefix[1]: [ a ]
─────────────────
difference: [ b | c | d ] ← this is sum(1, 3)
Why size n+1? The extra prefix[0] = 0 handles the edge case when l = 0:
sum(0, 2) = prefix[3] - prefix[0]
= (a + b + c) - 0
= a + b + c ✓
Without it, we’d need special if (left == 0) checks (see V0 in LC 303).
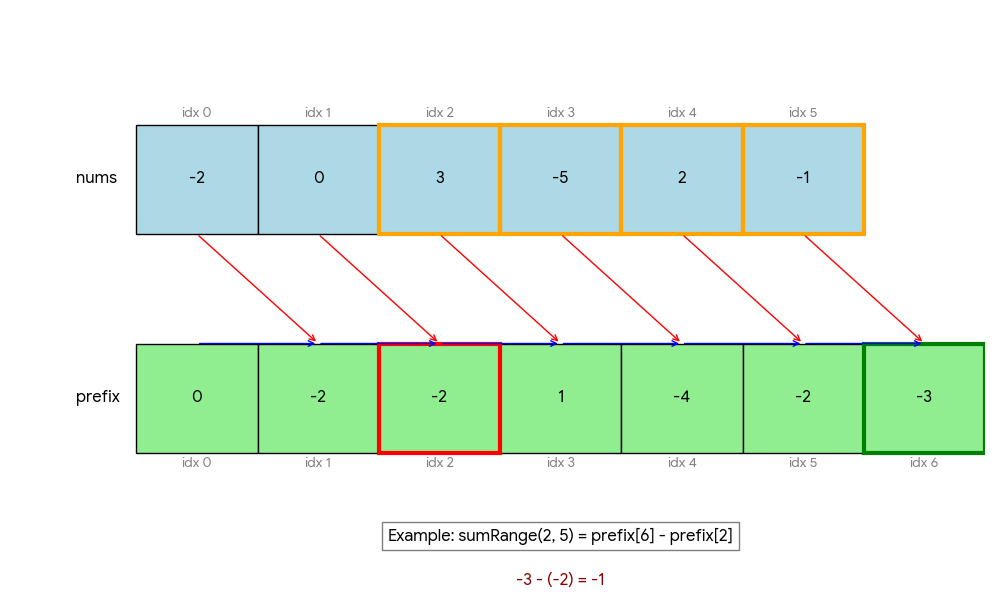
Concrete Example — LC 303
nums = [-2, 0, 3, -5, 2, -1]
Step 1: Build prefix array
prefix = [0, -2, -2, 1, -4, -2, -3]
↑ ↑ ↑ ↑ ↑ ↑
-2 -2+0 ... sum of all
Step 2: Query
sumRange(0, 2) = prefix[3] - prefix[0] = 1 - 0 = 1 ✓ (-2+0+3)
sumRange(2, 5) = prefix[6] - prefix[2] = -3 - (-2) = -1 ✓ (3-5+2-1)
sumRange(0, 5) = prefix[6] - prefix[0] = -3 - 0 = -3 ✓ (-2+0+3-5+2-1)
Two Styles Comparison
| Style | Prefix Size | Build | Query sum(l, r) |
Edge Case |
|---|---|---|---|---|
Size n+1 (recommended) |
n + 1 |
prefix[i+1] = prefix[i] + nums[i] |
prefix[r+1] - prefix[l] |
No special case needed |
Size n |
n |
prefix[i] = prefix[i-1] + nums[i] |
prefix[r] - (l > 0 ? prefix[l-1] : 0) |
Need if (l == 0) check |
Templates & Algorithms
Template Comparison Table
| Template Type | Use Case | Key Data Structure | When to Use |
|---|---|---|---|
| Basic Prefix Sum | Range sum queries | Array | Need multiple range sum calculations |
| HashMap + Prefix Sum | Subarray with target sum | HashMap | Find/count subarrays with specific sum |
| Modulo Prefix Sum | Divisibility problems | HashMap with remainders | Subarray sum divisible by k |
| Difference Array | Range updates | Array with start/end markers | Multiple range additions |
| 2D Prefix Sum | Rectangle sum queries | 2D matrix | 2D range sum calculations |
| Sum of Distances | Absolute difference sums | HashMap + Prefix Sum | Sum of |
Universal Template
def prefix_sum_solve(nums, target):
"""
Universal prefix sum template for most problems
"""
# Step 1: Initialize prefix sum and result
prefix_sum = 0
result = 0
# Step 2: HashMap for storing prefix sums (if needed)
prefix_map = {0: 1} # Handle subarrays starting from index 0
# Step 3: Iterate through array
for num in nums:
# Update prefix sum
prefix_sum += num
# Check condition based on problem type
if prefix_sum - target in prefix_map:
result += prefix_map[prefix_sum - target]
# Update map
prefix_map[prefix_sum] = prefix_map.get(prefix_sum, 0) + 1
return result
Template 1: Basic Prefix Sum (Range Queries) — LC 303
class PrefixSum:
def __init__(self, nums):
"""Build prefix sum array for range queries"""
self.prefix = [0] * (len(nums) + 1)
for i in range(len(nums)):
self.prefix[i + 1] = self.prefix[i] + nums[i]
def range_sum(self, left, right):
"""Get sum of elements from index left to right (inclusive)"""
return self.prefix[right + 1] - self.prefix[left]
// Java implementation
class PrefixSum {
private int[] prefix;
public PrefixSum(int[] nums) {
prefix = new int[nums.length + 1];
for (int i = 0; i < nums.length; i++) {
prefix[i + 1] = prefix[i] + nums[i];
}
}
public int rangeSum(int left, int right) {
return prefix[right + 1] - prefix[left];
}
}
Template 2: HashMap + Prefix Sum (Subarray Target Sum) — LC 560
def subarray_sum_equals_k(nums, k):
"""Count subarrays with sum equal to k"""
count = 0
prefix_sum = 0
prefix_map = {0: 1} # Important: initialize with {0: 1}
for num in nums:
prefix_sum += num
# Check if (prefix_sum - k) exists
if prefix_sum - k in prefix_map:
count += prefix_map[prefix_sum - k]
# Update map
prefix_map[prefix_sum] = prefix_map.get(prefix_sum, 0) + 1
return count
// Java implementation
public int subarraySum(int[] nums, int k) {
int count = 0, prefixSum = 0;
Map<Integer, Integer> map = new HashMap<>();
map.put(0, 1); // Handle subarrays starting from index 0
for (int num : nums) {
prefixSum += num;
if (map.containsKey(prefixSum - k)) {
count += map.get(prefixSum - k);
}
map.put(prefixSum, map.getOrDefault(prefixSum, 0) + 1);
}
return count;
}
Template 3: Modulo Prefix Sum (Divisibility Problems) — LC 974
Core Mathematical Insight:
Let prefix[i] = sum of nums[0..i]
A subarray sum nums[j+1..i] is divisible by k:
(prefix[i] - prefix[j]) % k == 0
This implies:
prefix[i] % k == prefix[j] % k
So if we see the SAME remainder again at index i vs a previous index j,
the subarray nums[j+1..i] has sum divisible by k.
map stores: { remainder -> earliest index }
If the current remainder already exists in the map
AND the distance (i - map[remainder]) >= 2, we found a valid subarray.
def subarray_divisible_by_k(nums, k):
"""Count subarrays with sum divisible by k"""
count = 0
prefix_sum = 0
remainder_map = {0: 1} # remainder -> count
for num in nums:
prefix_sum += num
remainder = prefix_sum % k
# Handle negative remainders
if remainder < 0:
remainder += k
if remainder in remainder_map:
count += remainder_map[remainder]
remainder_map[remainder] = remainder_map.get(remainder, 0) + 1
return count
Template 4: Difference Array (Range Updates) — LC 370
def range_addition(length, updates):
"""Apply multiple range additions efficiently"""
# Step 1: Create difference array
diff = [0] * (length + 1)
# Step 2: Apply range updates to difference array
for start, end, val in updates:
diff[start] += val
diff[end + 1] -= val
# Step 3: Compute prefix sum to get final result
result = []
current_sum = 0
for i in range(length):
current_sum += diff[i]
result.append(current_sum)
return result
Template 5: 2D Prefix Sum — LC 304
class NumMatrix:
def __init__(self, matrix):
"""Build 2D prefix sum matrix"""
if not matrix or not matrix[0]:
return
m, n = len(matrix), len(matrix[0])
self.prefix = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
self.prefix[i][j] = (matrix[i-1][j-1] +
self.prefix[i-1][j] +
self.prefix[i][j-1] -
self.prefix[i-1][j-1])
def sumRegion(self, row1, col1, row2, col2):
"""Calculate sum of rectangle from (row1,col1) to (row2,col2)"""
return (self.prefix[row2+1][col2+1] -
self.prefix[row1][col2+1] -
self.prefix[row2+1][col1] +
self.prefix[row1][col1])
Template 6: Transform and Count — LC 1248
def count_nice_subarrays(nums, k):
"""Count subarrays with exactly k odd numbers"""
# Transform: odd -> 1, even -> 0
transformed = [1 if x % 2 == 1 else 0 for x in nums]
# Now it's subarray sum equals k problem
count = 0
prefix_sum = 0
prefix_map = {0: 1}
for val in transformed:
prefix_sum += val
if prefix_sum - k in prefix_map:
count += prefix_map[prefix_sum - k]
prefix_map[prefix_sum] = prefix_map.get(prefix_sum, 0) + 1
return count
Template 7: Sum of Distances (Left-Right Split) — LC 2615
This pattern efficiently calculates sum of absolute differences |i - j| between indices.
Core Idea
For a sorted list of indices [i0, i1, i2, ..., ik], to find sum of distances from ij to all others:
Instead of: |ij - i0| + |ij - i1| + ... + |ij - ik| (O(n) per element)
Split into:
- Left part: (ij - i0) + (ij - i1) + ... = ij * countLeft - sumLeft
- Right part: (ij+1 - ij) + (ij+2 - ij) + ... = sumRight - ij * countRight
Total: (ij * countLeft - sumLeft) + (sumRight - ij * countRight)
Visual Explanation
Indices with same value: [2, 5, 8, 12]
↑ ↑ ↑ ↑
For index 8 (position 2 in list):
Left indices: [2, 5]
countLeft = 2
sumLeft = 2 + 5 = 7
distanceLeft = 8 * 2 - 7 = 9 → |8-2| + |8-5| = 6 + 3 = 9 ✓
Right indices: [12]
countRight = 1
sumRight = 12
distanceRight = 12 - 8 * 1 = 4 → |12-8| = 4 ✓
Total distance for index 8: 9 + 4 = 13
Python Template
def sum_of_distances(nums):
"""
LC 2615: Calculate sum of |i - j| for all j where nums[j] == nums[i]
Time: O(n), Space: O(n)
"""
from collections import defaultdict
n = len(nums)
result = [0] * n
# Step 1: Group indices by value
index_map = defaultdict(list)
for i, num in enumerate(nums):
index_map[num].append(i)
# Step 2: For each group, calculate distances using prefix sum
for indices in index_map.values():
m = len(indices)
if m == 1:
continue # Single element has distance 0
# Build prefix sum of indices
prefix = [0] * m
prefix[0] = indices[0]
for i in range(1, m):
prefix[i] = prefix[i - 1] + indices[i]
total_sum = prefix[m - 1]
# Calculate distance for each index in group
for i in range(m):
idx = indices[i]
# Left part: idx * countLeft - sumLeft
count_left = i
sum_left = prefix[i - 1] if i > 0 else 0
left_dist = idx * count_left - sum_left
# Right part: sumRight - idx * countRight
count_right = m - i - 1
sum_right = total_sum - prefix[i]
right_dist = sum_right - idx * count_right
result[idx] = left_dist + right_dist
return result
Java Template
// LC 2615 - Sum of Distances
public long[] distance(int[] nums) {
int n = nums.length;
long[] res = new long[n];
Map<Integer, List<Integer>> map = new HashMap<>();
// Step 1: Group indices by value
for (int i = 0; i < n; i++) {
map.computeIfAbsent(nums[i], k -> new ArrayList<>()).add(i);
}
// Step 2: Calculate distances using prefix sum
for (List<Integer> indices : map.values()) {
int m = indices.size();
if (m == 1) continue;
// Build prefix sum
long[] prefix = new long[m];
prefix[0] = indices.get(0);
for (int i = 1; i < m; i++) {
prefix[i] = prefix[i - 1] + indices.get(i);
}
// Calculate distance for each index
for (int i = 0; i < m; i++) {
int idx = indices.get(i);
// Left: idx * countLeft - sumLeft
long left = (long) idx * i - (i == 0 ? 0 : prefix[i - 1]);
// Right: sumRight - idx * countRight
long right = (prefix[m - 1] - prefix[i]) - (long) idx * (m - i - 1);
res[idx] = left + right;
}
}
return res;
}
Template 8: Prefix Maximum (Greedy Chunk / Partition) — LC 769
Core Idea: For a permutation of [0, n-1], the prefix arr[0..i] can be an independent sorted chunk if and only if max(arr[0..i]) == i. Track this with a single maxSoFar variable.
// Java — LC 769 Max Chunks To Make Sorted
// Time: O(n) Space: O(1)
public int maxChunksToSorted(int[] arr) {
int chunks = 0, maxSoFar = 0;
for (int i = 0; i < arr.length; i++) {
maxSoFar = Math.max(maxSoFar, arr[i]);
if (maxSoFar == i) chunks++; // all values 0..i are present in arr[0..i]
}
return chunks;
}
# Python — LC 769
def maxChunksToSorted(arr):
chunks = max_so_far = 0
for i, val in enumerate(arr):
max_so_far = max(max_so_far, val)
if max_so_far == i:
chunks += 1
return chunks
Equivalent prefix-sum formulation (also O(n)/O(1)):
// prefixSum of arr == prefixSum of sorted arr → same multiset in [0..i]
int chunks = 0, prefixSum = 0, sortedPrefixSum = 0;
for (int i = 0; i < arr.length; i++) {
prefixSum += arr[i];
sortedPrefixSum += i; // sorted array is [0,1,2,...,n-1]
if (prefixSum == sortedPrefixSum) chunks++;
}
When to upgrade to PrefixMax + SuffixMin (LC 768, general arrays):
// If values are NOT a permutation, use:
// max(arr[0..i-1]) < min(arr[i..n-1]) → valid cut point
int[] prefixMax = arr.clone(), suffixMin = arr.clone();
for (int i = 1; i < n; i++) prefixMax[i] = Math.max(prefixMax[i-1], prefixMax[i]);
for (int i = n-2; i >= 0; i--) suffixMin[i] = Math.min(suffixMin[i+1], suffixMin[i]);
int chunks = 0;
for (int i = 0; i < n; i++)
if (i == 0 || suffixMin[i] > prefixMax[i-1]) chunks++;
Alternative: Running Sum Approach (No Prefix Array)
def sum_of_distances_optimized(nums):
"""Space-optimized version using running sums"""
from collections import defaultdict
n = len(nums)
result = [0] * n
index_map = defaultdict(list)
for i, num in enumerate(nums):
index_map[num].append(i)
for indices in index_map.values():
m = len(indices)
if m == 1:
continue
# Calculate total sum once
total_sum = sum(indices)
prefix_sum = 0
for i, idx in enumerate(indices):
# Left: idx * i - prefix_sum
# Right: (total_sum - prefix_sum - idx) - idx * (m - i - 1)
left_dist = idx * i - prefix_sum
right_dist = (total_sum - prefix_sum - idx) - idx * (m - i - 1)
result[idx] = left_dist + right_dist
prefix_sum += idx
return result
Formula Summary
| Component | Formula | Meaning |
|---|---|---|
| Left Distance | idx * countLeft - sumLeft |
Sum of (idx - smaller_idx) |
| Right Distance | sumRight - idx * countRight |
Sum of (larger_idx - idx) |
| Total Distance | leftDist + rightDist |
Sum of all |idx - other_idx| |
Problems by Pattern
Pattern-Based Problem Classification
Pattern 1: Basic Range Sum Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Range Sum Query - Immutable | 303 | Basic prefix sum array | Easy | Template 1 |
| Range Sum Query 2D - Immutable | 304 | 2D prefix sum | Medium | Template 5 |
| Product of Array Except Self | 238 | Left/right prefix products | Medium | Modified Template 1 |
| Running Sum of 1d Array | 1480 | Direct prefix sum | Easy | Template 1 |
| Find Pivot Index | 724 | Left sum vs right sum | Easy | Template 1 |
Pattern 2: Subarray Sum Equals Target Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Subarray Sum Equals K | 560 | HashMap + prefix sum | Medium | Template 2 |
| Maximum Size Subarray Sum Equals k | 325 | HashMap with indices | Medium | Template 2 |
| Subarray Sum Equals K II | 713 | Product version | Medium | Modified Template 2 |
| Binary Subarrays With Sum | 930 | Transform to sum equals | Medium | Template 6 |
| Number of Subarrays with Bounded Maximum | 795 | Range sum technique | Medium | Template 2 |
| Longest Well-Performing Interval | 1124 | First-occurrence map + score-1 trick | Medium | Template 2 variant |
Pattern 3: Subarray with Divisibility/Modulo Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Subarray Sums Divisible by K | 974 | Modulo prefix sum | Medium | Template 3 |
| Continuous Subarray Sum | 523 | Modulo with length check | Medium | Template 3 |
| Make Sum Divisible by P | 1590 | Advanced modulo technique | Medium | Template 3 |
| Check If Array Pairs Are Divisible by k | 1497 | Frequency of remainders | Medium | Modified Template 3 |
Pattern 4: Range Addition/Updates Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Range Addition | 370 | Difference array | Medium | Template 4 |
| Car Pooling | 1094 | Timeline simulation | Medium | Template 4 |
| Corporate Flight Bookings | 1109 | Range updates | Medium | Template 4 |
| Maximum Population Year | 1854 | Event processing | Easy | Template 4 |
| Meeting Rooms II | 253 | Overlap counting | Medium | Template 4 |
Pattern 5: 2D Matrix Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Range Sum Query 2D | 304 | 2D prefix sum | Medium | Template 5 |
| Matrix Block Sum | 1314 | 2D range queries | Medium | Template 5 |
| Number of Submatrices That Sum to Target | 1074 | 2D + HashMap | Hard | Template 5 + 2 |
| Maximum Side Length Square | 1292 | Binary search + 2D prefix | Medium | Template 5 |
Pattern 6: Transform and Count Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Count Number of Nice Subarrays | 1248 | Transform odd/even | Medium | Template 6 |
| Flip String to Monotone Increasing | 926 | Transform 0/1 counting | Medium | Template 6 |
| Max Chunks To Make Sorted | 769 | Sum comparison | Medium | Template 6 |
| Longest Arithmetic Subsequence | 1027 | Transform differences | Medium | Template 6 |
Pattern 7: Sum of Distances Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Sum of Distances | 2615 | Group + left-right split | Medium | Template 7 |
| Intervals Between Identical Elements | 2121 | Same pattern, intervals | Medium | Template 7 |
| Sum of Absolute Differences in a Sorted Array | 1685 | Sorted array variant | Medium | Template 7 |
| Sum of Distances in Tree | 834 | Tree version (DFS + reroot) | Hard | Template 7 + DFS |
| Minimum Total Distance Traveled | 2463 | DP + distance calculation | Hard | Template 7 + DP |
Pattern 8: Prefix Maximum Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Max Chunks To Make Sorted | 769 | Prefix max == index | Medium | Template 8 |
| Max Chunks To Make Sorted II | 768 | PrefixMax + SuffixMin arrays | Hard | Template 8 |
| Find the Longest Turbulent Subarray | 978 | Running state tracking | Medium | Modified Template 8 |
Advanced/Mixed Pattern Problems
| Problem | LC # | Key Technique | Difficulty | Template |
|---|---|---|---|---|
| Maximum Sum of Two Non-Overlapping Subarrays | 1031 | Multiple prefix arrays | Medium | Template 1 + DP |
| Subarrays with K Different Integers | 992 | At most K technique | Hard | Template 2 |
| Minimum Window Subsequence | 727 | Sliding window + prefix | Hard | Template 2 + SW |
| Split Array With Same Average | 805 | Subset sum problem | Hard | Template 2 |
| Largest Rectangle in Histogram | 84 | Stack + prefix sum | Hard | Template 1 + Stack |
Additional Practice Problems
Easy Problems (Foundation Building)
| Problem | LC # | Focus Area | Template |
|---|---|---|---|
| Two Sum | 1 | HashMap fundamentals | Modified Template 2 |
| Contains Duplicate II | 219 | Sliding window + map | Template 2 |
| Maximum Average Subarray I | 643 | Fixed size subarray | Template 1 |
| Degree of an Array | 697 | Element frequency | Template 2 |
Medium Problems (Core Patterns)
| Problem | LC # | Focus Area | Template |
|---|---|---|---|
| Contiguous Array | 525 | Balance 0s and 1s | Template 6 |
| Shortest Unsorted Continuous Subarray | 581 | Array analysis | Template 1 |
| Random Pick with Weight | 528 | Weighted random | Template 1 |
| Path Sum III | 437 | Tree + prefix sum | Template 2 |
Hard Problems (Advanced Techniques)
| Problem | LC # | Focus Area | Template |
|---|---|---|---|
| Count of Range Sum | 327 | Merge sort + prefix | Advanced |
| Reverse Pairs | 493 | Merge sort technique | Advanced |
| Create Maximum Number | 321 | Greedy + prefix | Advanced |
| Count Different Palindromic Subsequences | 730 | DP + prefix | Advanced |
Pattern Selection Strategy
Decision Framework for Prefix Sum Problems
Problem Analysis Flowchart:
1. Need multiple range sum queries?
├── YES → Use Template 1 (Basic Prefix Sum)
└── NO → Continue to 2
2. Looking for subarrays with specific sum/count?
├── YES → Continue to 2a
└── NO → Continue to 3
2a. Exact sum target?
├── YES → Use Template 2 (HashMap + Prefix Sum)
└── NO → Continue to 2b
2b. Divisibility or modulo involved?
├── YES → Use Template 3 (Modulo Prefix Sum)
└── NO → Continue to 2c
2c. Count odd/even or binary transformation?
├── YES → Use Template 6 (Transform and Count)
└── NO → Use Template 2
3. Multiple range updates needed?
├── YES → Use Template 4 (Difference Array)
└── NO → Continue to 4
4. 2D matrix operations?
├── YES → Use Template 5 (2D Prefix Sum)
└── NO → Continue to 5
5. Special cases:
├── Product instead of sum → Modified Template 1
├── Tree path sums → Template 2 + Tree traversal
├── Sliding window + prefix → Combine templates
└── Advanced merge/sort → Custom approach
Template Selection Guide
| Problem Keywords | Recommended Template | Example Problems |
|---|---|---|
| “range sum”, “query” | Template 1 | LC 303, 304 |
| “subarray sum equals”, “count subarrays” | Template 2 | LC 560, 325 |
| “divisible by”, “remainder”, “modulo” | Template 3 | LC 974, 523 |
| “range addition”, “updates”, “intervals” | Template 4 | LC 370, 1094 |
| “2D”, “matrix”, “rectangle” | Template 5 | LC 304, 1314 |
| “odd numbers”, “binary”, “transform” | Template 6 | LC 1248, 926 |
| “sum of distances”, “absolute differences”, “identical elements” | Template 7 | LC 2615, 2121, 1685 |
| “max chunks”, “partition to sort”, “split into sorted segments” | Template 8 | LC 769, 768 |
Problem Identification Patterns
Identify Template 1 Usage:
- Problem mentions: “range sum query”, “immutable array”, “multiple queries”
- Input: Array + multiple (left, right) queries
- Output: Sum of elements in range [left, right]
Identify Template 2 Usage:
- Problem mentions: “subarray sum equals K”, “count subarrays”, “target sum”
- Key insight: Need to find pairs (i, j) where
prefixSum[j] - prefixSum[i] = target - HashMap stores:
{prefixSum: count}or{prefixSum: index}
Identify Template 3 Usage:
- Problem mentions: “divisible by K”, “remainder”, “modulo”, “continuous sum”
- Key insight:
(prefixSum[j] - prefixSum[i]) % k = 0means same remainders - HashMap stores:
{remainder: count}or{remainder: index}
Identify Template 4 Usage:
- Problem mentions: “range updates”, “add value to range”, “difference array”
- Multiple operations of type: “add val to indices [start, end]”
- Key insight: Mark start/end points, then compute prefix sum
Identify Template 5 Usage:
- Problem mentions: “2D matrix”, “rectangle sum”, “submatrix”
- Need sum of rectangle from (r1,c1) to (r2,c2)
- Formula:
total - left - top + topleft
Identify Template 6 Usage:
- Problem mentions: “count odd/even”, “binary conditions”, “transform array”
- First transform array (e.g., odd→1, even→0), then apply prefix sum
- Reduces to simpler prefix sum problem
Identify Template 7 Usage:
- Problem mentions: “sum of distances”, “absolute differences”, “identical elements”
- Need to calculate
sum of |i - j|for elements with same value - Key insight: Split into left/right parts, use
count * value - sumformula - HashMap stores:
{value: [list of indices]} - Time complexity reduces from O(n²) to O(n)
Identify Template 8 Usage:
- Problem mentions: “max chunks”, “partition array so each part can be sorted independently”, “split to sort”
- Input array is a permutation of
[0, n-1](or can be generalized with prefix/suffix arrays) - Key insight:
maxSoFar == imeans prefix[0..i]is a complete, self-contained set ready to sort - Equivalent check: prefix sum of
arr[0..i]equals prefix sum of sorted array[0..i]
Legacy Examples
0-2-1) Get count of continuous sub array equals to K
// java
// LC 560
// ..
Map<Integer, Integer> map = new HashMap<>();
// ..
for (int num : nums) {
presum += num;
// Check if there's a prefix sum such that presum - k exists
// NOTE !!! below
if (map.containsKey(presum - k)) {
count += map.get(presum - k);
}
// Update the map with the current prefix sum
map.put(presum, map.getOrDefault(presum, 0) + 1);
}
// ..
0-2-2) get prefix with range addition
// java
// LC 1094
// ...
int[] prefixSum = new int[1001]; // the biggest array size given by problem
// `init pre prefix sum`
for (int[] t : trips) {
int amount = t[0];
int start = t[1];
int end = t[2];
/**
* NOTE !!!!
*
* via trick below, we can `efficiently` setup prefix sum
* per start, end index
*
* -> we ADD amount at start point (customer pickup up)
* -> we MINUS amount at `end point` (customer drop off)
*
* -> via above, we get the `adjusted` `init prefix sum`
* -> so all we need to do next is :
* -> loop over the `init prefix sum`
* -> and keep adding `previous to current val`
* -> e.g. prefixSum[i] = prefixSum[i-1] + prefixSum[i]
*
*/
prefixSum[start] += amount;
prefixSum[end] -= amount;
}
// update `prefix sum` array
for (int i = 1; i < prefixSum.length; i++) {
prefixSum[i] += prefixSum[i - 1];
}
// ...
1) LC Example
1-1) Flip String to Monotone Increasing — LC 926
# LC 926. Flip String to Monotone Increasing
# NOTE : there is also dp approaches
# V0
# IDEA : PREFIX SUM
class Solution(object):
def minFlipsMonoIncr(self, S):
# get pre-fix sum
P = [0]
for x in S:
P.append(P[-1] + int(x))
# find min
res = float('inf')
for j in range(len(P)):
res = min(res, P[j] + len(S)-j-(P[-1]-P[j]))
return res
# V1
# IDEA : PREFIX SUM
# https://leetcode.com/problems/flip-string-to-monotone-increasing/solution/
class Solution(object):
def minFlipsMonoIncr(self, S):
# get pre-fix sum
P = [0]
for x in S:
P.append(P[-1] + int(x))
# return min
return min(P[j] + len(S)-j-(P[-1]-P[j])
for j in range(len(P)))
1-2) Range Addition — LC 370
# LC 370. Range Addition
# V0
# IDEA : double loop -> 2 single loops, prefix sum
class Solution(object):
def getModifiedArray(self, length, updates):
# edge case
if not length:
return
if length and not updates:
return [0 for i in range(length)]
# init res
res = [0 for i in range(length)]
# get cumsum on start and end idx
# then go through res, adjust the sum
for _start, _end, val in updates:
res[_start] += val
if _end+1 < length:
res[_end+1] -= val
#print ("res = " + str(res))
cur = 0
for i in range(len(res)):
cur += res[i]
res[i] = cur
#print ("--> res = " + str(res))
return res
# V0'
# IDEA : double loop -> 2 single loops, prefix sum
class Solution(object):
def getModifiedArray(self, length, updates):
# NOTE : we init res with (len+1)
res = [0] * (length + 1)
"""
NOTE !!!
-> We split double loop into 2 single loops
-> Steps)
step 1) go through updates, add val to start and end idx in res
step 2) go through res, maintain an aggregated sum (sum) and add it to res[i]
e.g. res[i], sum = res[i] + sum, res[i] + sum
"""
for start, end, val in updates:
res[start] += val
res[end+1] -= val
sum = 0
for i in range(0, length):
res[i], sum = res[i] + sum, res[i] + sum
# NOTE : we return res[0:-1]
return res[0:-1]
# V0'
# IDEA : double loop -> 2 single loops, prefix sum
class Solution(object):
def getModifiedArray(self, length, updates):
ret = [0] * (length + 1)
for start, end, val in updates:
ret[start] += val
ret[end+1] -= val
sum = 0
for i in range(0, length):
ret[i], sum = ret[i] + sum, ret[i] + sum
return ret[0:-1]
1-3) Count Number of Nice Subarrays — LC 1248
# 1248. Count Number of Nice Subarrays
# NOTE : there are also array, window, deque.. approaches
class Solution:
def numberOfSubarrays(self, nums, k):
d = collections.defaultdict(int)
"""
definition of hash map (in this problem)
-> d[cum_sum] = number_of_cum_sum_till_now
-> so at beginning, cum_sum = 0, and its count = 1
-> so we init hash map via "d[0] = 1"
"""
d[0] = 1
# init cum_sum
cum_sum = 0
res = 0
# go to each element
for i in nums:
### NOTE : we need to check "if i % 2 == 1" first, so in the next logic, we can append val to result directly
if i % 2 == 1:
cum_sum += 1
"""
NOTE !!! : trick here !!!
-> same as 2 sum ...
-> if cum_sum - x == k
-> x = cum_sum - k
-> so we need to check if "cum_sum - k" already in our hash map
"""
if cum_sum - k in d:
### NOTE !!! here : we need to use d[cum_sum - k], since this is # of sub string combination that with # of odd numbers == k
res += d[cum_sum - k]
### NOTE !!! : we need to add 1 to count of "cum_sum", since in current loop, we got a new cur_sum (as above)
d[cum_sum] += 1
return res
1-4) Maximum Size Subarray Sum Equals k — LC 325
# LC 325. Maximum Size Subarray Sum Equals k
# V0
# time complexity : O(N) | space complexity : O(N)
# IDEA : HASH TBALE
# -> have a var acc keep sum of all item in nums,
# -> and use dic collect acc and its index
# -> since we want to find nums[i:j] = k -> so it's a 2 sum problem now
# -> i.e. if acc - k in dic => there must be a solution (i,j) of nums[i:j] = k
# -> return the max result
# -> ### acc DEMO : given array a = [1,2,3,4,5] ###
# -> acc_list = [1,3,6,10,15]
# -> so sum(a[1:3]) = 9 = acc_list[3] - acc_list[1-1] = 10 - 1 = 9
class Solution(object):
def maxSubArrayLen(self, nums, k):
result, acc = 0, 0
# NOTE !!! we init dic as {0:-1} ({sum:idx})
dic = {0: -1}
for i in range(len(nums)):
acc += nums[i]
if acc not in dic:
### NOTE : we save idx as dict value
dic[acc] = i
### acc - x = k -> so x = acc - k, that's why we check if acc - x in the dic or not
if acc - k in dic:
result = max(result, i - dic[acc-k])
return result
1-5) Subarray Sum Equals K — LC 560
// java
// LC 560
public int subarraySum(int[] nums, int k) {
/**
* NOTE !!!
*
* use Map to store prefix sum and its count
*
* map : {prefixSum: count}
*
*
* -> since "same preSum may have multiple combination" within hashMap,
* so it's needed to track preSum COUNT, instead of its index
*/
Map<Integer, Integer> map = new HashMap<>();
int presum = 0;
int count = 0;
/**
* NOTE !!!
*
* Initialize the map with prefix sum 0 (to handle subarrays starting at index 0)
*/
map.put(0, 1);
for (int num : nums) {
presum += num;
// Check if there's a prefix sum such that presum - k exists
if (map.containsKey(presum - k)) {
count += map.get(presum - k);
}
// Update the map with the current prefix sum
map.put(presum, map.getOrDefault(presum, 0) + 1);
}
return count;
}
1-6) Continuous Subarray Sum — LC 523
// java
// LC 523
// V1
// IDEA : HASHMAP
// https://leetcode.com/problems/continuous-subarray-sum/editorial/
// https://github.com/yennanliu/CS_basics/blob/master/doc/pic/presum_mod.png
public boolean checkSubarraySum_1(int[] nums, int k) {
int prefixMod = 0;
HashMap<Integer, Integer> modSeen = new HashMap<>();
modSeen.put(0, -1);
for (int i = 0; i < nums.length; i++) {
/**
* NOTE !!! we get `mod of prefixSum`, instead of get prefixSum
*/
prefixMod = (prefixMod + nums[i]) % k;
if (modSeen.containsKey(prefixMod)) {
// ensures that the size of subarray is at least 2
if (i - modSeen.get(prefixMod) > 1) {
return true;
}
} else {
// mark the value of prefixMod with the current index.
modSeen.put(prefixMod, i);
}
}
return false;
}
1-7) Max Chunks To Make Sorted — LC 769
// java
// LC 769
// V1-1
// https://leetcode.com/problems/max-chunks-to-make-sorted/editorial/
// IDEA: Prefix Sums
/**
* IDEA:
*
* An important observation is that a segment of the
* array can form a valid chunk if, when sorted,
* it matches the corresponding segment
* in the fully sorted version of the array.
*
* Since the numbers in arr belong to the range [0, n - 1], we can simplify the problem by using the property of sums. Specifically, for any index, it suffices to check whether the sum of the elements in arr up to that index is equal to the sum of the elements in the corresponding prefix of the sorted array.
*
* If these sums are equal, it guarantees that the elements in the current segment of arr match the elements in the corresponding segment of the sorted array (possibly in a different order). When this condition is satisfied, we can form a new chunk — either starting from the beginning of the array or the end of the previous chunk.
*
* For example, consider arr = [1, 2, 0, 3, 4] and the sorted version sortedArr = [0, 1, 2, 3, 4]. We find the valid segments as follows:
*
* Segment [0, 0] is not valid, since sum = 1 and sortedSum = 0.
* Segment [0, 1] is not valid, since sum = 1 + 2 = 3 and sortedSum = 0 + 1 = 1.
* Segment [0, 2] is valid, since sum = 1 + 2 + 0 = 3 and sortedSum = 0 + 1 + 2 = 3.
* Segment [3, 3] is valid, because sum = 1 + 2 + 0 + 3 = 6 and sortedSum = 0 + 1 + 2 + 3 = 6.
* Segment [4, 4] is valid, because sum = 1 + 2 + 0 + 3 + 4 = 10 and sortedSum = 0 + 1 + 2 + 3 + 4 = 10.
* Therefore, the answer here is 3.
*
* Algorithm
* - Initialize n to the size of the arr array.
* - Initialize chunks, prefixSum, and sortedPrefixSum to 0.
* - Iterate over arr with i from 0 to n - 1:
* - Increment prefixSum by arr[i].
* - Increment sortedPrefixSum by i.
* - Check if prefixSum == sortedPrefixSum:
* - If so, increment chunks by 1.
* - Return chunks.
*
*/
public int maxChunksToSorted_1_1(int[] arr) {
int n = arr.length;
int chunks = 0, prefixSum = 0, sortedPrefixSum = 0;
// Iterate over the array
for (int i = 0; i < n; i++) {
// Update prefix sum of `arr`
prefixSum += arr[i];
// Update prefix sum of the sorted array
sortedPrefixSum += i;
// If the two sums are equal, the two prefixes contain the same elements; a chunk can be formed
if (prefixSum == sortedPrefixSum) {
chunks++;
}
}
return chunks;
}
1-8) Maximum Sum of Two Non-Overlapping Subarrays — LC 1031
Core Idea (LC 1031):
Given two non-overlapping windows of fixed lengths L and M, maximize their combined sum.
Key Insight: one window must come before the other. Handle both orderings separately:
- Case 1: L-window appears before M-window
- Case 2: M-window appears before L-window
For each position i (right edge of the second window), track the maximum
sum of the first window seen so far (t), then combine with the current second window.
Prefix sum formula for a window of length W ending at index i (1-based):
window_sum = prefix[i] - prefix[i - W]
At each step:
t = max(t, prefix[i - M] - prefix[i - M - L]) ← best L-window before M starts
ans = max(ans, t + prefix[i] - prefix[i - M]) ← best L + current M
Why two passes? The two window orders (L before M, M before L) are
independent. The overall answer is max of both passes.
Pattern: Prefix Sum + Running Maximum (two-pass)
- Build prefix sum array once: O(n)
- For each pass, slide the second window right while maintaining
maxFirst(best first window so far) - Two passes cover all non-overlapping configurations
// java
// LC 1031 — Prefix Sum + Running Max
// time: O(N), space: O(N)
public int maxSumTwoNoOverlap(int[] nums, int firstLen, int secondLen) {
int n = nums.length;
int[] s = new int[n + 1];
for (int i = 0; i < n; ++i) {
s[i + 1] = s[i] + nums[i];
}
int ans = 0;
// Case 1: firstLen window comes before secondLen window
// i is the right edge (exclusive) of the secondLen window
for (int i = firstLen, t = 0; i + secondLen - 1 < n; ++i) {
// best firstLen window that ends at or before position i (before M starts)
t = Math.max(t, s[i] - s[i - firstLen]);
// current secondLen window starting at i
ans = Math.max(ans, t + s[i + secondLen] - s[i]);
}
// Case 2: secondLen window comes before firstLen window
for (int i = secondLen, t = 0; i + firstLen - 1 < n; ++i) {
t = Math.max(t, s[i] - s[i - secondLen]);
ans = Math.max(ans, t + s[i + firstLen] - s[i]);
}
return ans;
}
Alternative helper-function style (cleaner):
// Calls helper(L before M) and helper(M before L), returns max
public int maxSumTwoNoOverlap(int[] nums, int firstLen, int secondLen) {
int n = nums.length;
int[] prefix = new int[n + 1];
for (int i = 0; i < n; i++) prefix[i + 1] = prefix[i] + nums[i];
return Math.max(helper(prefix, firstLen, secondLen),
helper(prefix, secondLen, firstLen));
}
// L comes before M
private int helper(int[] prefix, int L, int M) {
int maxL = 0, res = 0;
for (int i = L + M; i < prefix.length; i++) {
// best L-window ending just before the M-window
maxL = Math.max(maxL, prefix[i - M] - prefix[i - M - L]);
// current M-window
res = Math.max(res, maxL + prefix[i] - prefix[i - M]);
}
return res;
}
Python (prefix sum + running max):
# python
# LC 1031 — Prefix Sum + Running Max
# time: O(N), space: O(N)
# ref: leetcode_python/Array/maximum-sum-of-two-non-overlapping-subarrays.py
class Solution:
def maxSumTwoNoOverlap(self, nums, firstLen, secondLen):
n = len(nums)
# prefix[i] = sum(nums[:i]) (size n+1, prefix[0] = 0 sentinel)
prefix = [0] * (n + 1)
for i in range(n):
prefix[i + 1] = prefix[i] + nums[i]
# maxSum(L, M): best combined sum when the L-window is BEFORE the M-window
def maxSum(L, M):
# bestL = best L-window seen so far, ending before the current M-window
bestL = prefix[L] - prefix[0]
ans = 0
# i = starting index of the M-window
for i in range(L, n - M + 1):
# update best L-window ending at index i (i.e. nums[i-L:i])
bestL = max(bestL, prefix[i] - prefix[i - L])
# current M-window = nums[i:i+M]
currM = prefix[i + M] - prefix[i]
ans = max(ans, bestL + currM)
return ans
# try BOTH orders: L-before-M and M-before-L
return max(maxSum(firstLen, secondLen),
maxSum(secondLen, firstLen))
Why this is correct (core idea recap):
1. Core idea
- Two fixed-length windows (L and M) that must NOT overlap.
- One window is always fully to the left of the other, so enumerate
both orderings and take the max.
- Within one ordering, freeze the M-window's start (i), then the best
L-window is any L-window ending at/before i — track it as a running
max `bestL` so each i costs O(1).
2. Pattern
- Prefix Sum (O(1) window sum) + Running Maximum (best left window so far).
- Single left-to-right sweep per ordering → 2 sweeps total, O(n) each.
- window_sum for length W ending at index i: prefix[i] - prefix[i - W]
3. Similar LC → see table below
Similar LCs:
| Problem | LC # | Similarity |
|---|---|---|
| Maximum Subarray | 53 | Running max subarray (Kadane’s) |
| Best Time to Buy and Sell Stock III | 123 | Two non-overlapping operations, prefix+suffix |
| Maximum Sum of 3 Non-Overlapping Subarrays | 689 | Same pattern extended to 3 windows |
| Subarray Sum Equals K | 560 | Prefix sum + HashMap |
| Maximum Average Subarray II | 644 | Fixed/variable window with prefix sum |
1-9) Maximum Side Length of a Square with Sum ≤ Threshold — LC 1292
Pattern: 2D Prefix Sum + Binary Search or 2D Prefix Sum + Greedy
Core Idea:
- Build a 2D prefix sum table (size
(m+1) x (n+1)) so any square’s sum is computed in O(1). - Binary Search approach: Binary search on side length
[1, min(m,n)]. For each candidate lengthmid, scan all valid top-left corners and check if any square sum ≤ threshold. → O(m·n·log(min(m,n))) - Greedy approach: Single pass over all cells; at each cell
(i,j), only test if a square of sidemaxSide+1fits. If yes, incrementmaxSide. → O(m·n)
2D Prefix Sum formula (square ending at (i,j) with side k):
sum = P[i][j] - P[i-k][j] - P[i][j-k] + P[i-k][j-k]
Binary Search approach (Java):
// LC 1292 - V1 Binary Search
public int maxSideLength(int[][] mat, int threshold) {
int m = mat.length, n = mat[0].length;
int[][] P = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
P[i][j] = mat[i-1][j-1] + P[i-1][j] + P[i][j-1] - P[i-1][j-1];
int l = 1, r = Math.min(m, n), ans = 0;
while (l <= r) {
int mid = (l + r) / 2;
boolean found = false;
outer:
for (int i = mid; i <= m; i++) {
for (int j = mid; j <= n; j++) {
int sum = P[i][j] - P[i-mid][j] - P[i][j-mid] + P[i-mid][j-mid];
if (sum <= threshold) { found = true; break outer; }
}
}
if (found) { ans = mid; l = mid + 1; }
else r = mid - 1;
}
return ans;
}
Greedy approach (Java):
// LC 1292 - V0 Greedy (O(m*n), optimal)
public int maxSideLength(int[][] mat, int threshold) {
int m = mat.length, n = mat[0].length;
int[][] P = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
P[i][j] = mat[i-1][j-1] + P[i-1][j] + P[i][j-1] - P[i-1][j-1];
int maxSide = 0;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
int k = maxSide + 1; // only try to improve by 1
if (i >= k && j >= k) {
int sum = P[i][j] - P[i-k][j] - P[i][j-k] + P[i-k][j-k];
if (sum <= threshold) maxSide++;
}
}
}
return maxSide;
}
Why Greedy works: We only need to know the maximum achievable side length. Scanning left-to-right, top-to-bottom ensures we never miss a valid square — if a larger square exists somewhere, it will be discovered when we reach its bottom-right corner.
Similar LCs:
| Problem | LC # | Similarity |
|---|---|---|
| Range Sum Query 2D | 304 | Core 2D prefix sum template |
| Matrix Block Sum | 1314 | Fixed-radius 2D range query |
| Number of Submatrices That Sum to Target | 1074 | 2D prefix sum + count (harder) |
| Maximal Square | 221 | Max square in matrix (DP approach) |
| Largest 1-Bordered Square | 1139 | Max square with border condition |
1-10) Longest Well-Performing Interval — LC 1124
Pattern: HashMap + Prefix Sum — Longest Subarray with Positive Sum
Core Idea:
Transform each day: tiring (hours[i] > 8) → +1, non-tiring → -1. The problem becomes: find the longest subarray whose sum > 0.
At each index i with running prefix sum p:
Case 1: p > 0
→ entire interval [0..i] is valid
→ length = i + 1
Case 2: p ≤ 0
→ look for the earliest index j where prefix[j] = p - 1
→ subarray [j+1..i] has sum = p - (p-1) = 1 > 0
→ length = i - j
Why (p - 1)?
We want the LONGEST span ending at i with a net positive sum.
That means we need the SMALLEST prefix sum just one below the current value,
recorded at the EARLIEST index possible — hence putIfAbsent (first occurrence only).
Key Difference from Template 2:
- Template 2 stores
{prefix_sum: count}for counting subarrays. - This variant stores
{prefix_sum: first_index}for maximum length — only the first occurrence matters because an earlier start gives a longer interval.
Java Code:
// LC 1124 — Time: O(n), Space: O(n)
public int longestWPI(int[] hours) {
Map<Integer, Integer> map = new HashMap<>();
int prefix = 0, maxLen = 0;
for (int i = 0; i < hours.length; i++) {
prefix += hours[i] > 8 ? 1 : -1;
if (prefix > 0) {
maxLen = i + 1; // whole prefix is valid
} else {
if (map.containsKey(prefix - 1)) {
maxLen = Math.max(maxLen, i - map.get(prefix - 1));
}
}
map.putIfAbsent(prefix, i); // first occurrence only
}
return maxLen;
}
Similar LCs:
| Problem | LC # | Similarity |
|---|---|---|
| Contiguous Array | 525 | Longest subarray with equal 0s and 1s — same pattern, target sum = 0 |
| Maximum Size Subarray Sum Equals k | 325 | Longest subarray with sum = k, first-occurrence map |
| Subarray Sum Equals K | 560 | Count variant (store count, not index) |
| Binary Subarrays With Sum | 930 | Count subarrays with binary-transformed sum = k |
1-11) Sum of Distances — LC 2615
// java
// LC 2615 - Sum of Distances
// IDEA: HashMap + Prefix Sum (Left-Right Split)
/**
* Core Formula:
* For index i in a group of identical elements:
* - leftDistance = i * countLeft - sumLeft
* - rightDistance = sumRight - i * countRight
* - totalDistance = leftDistance + rightDistance
*
* Why this works:
* |i - j| for all j < i = (i - j1) + (i - j2) + ...
* = i * count - (j1 + j2 + ...)
* = i * countLeft - sumLeft
*/
public long[] distance(int[] nums) {
int n = nums.length;
long[] res = new long[n];
Map<Integer, List<Integer>> map = new HashMap<>();
// Step 1: Group indices by value
for (int i = 0; i < n; i++) {
map.computeIfAbsent(nums[i], k -> new ArrayList<>()).add(i);
}
// Step 2: For each group, calculate distances using prefix sum
for (List<Integer> list : map.values()) {
int m = list.size();
if (m == 1) continue; // Single element has distance 0
// Build prefix sum of indices
long[] prefix = new long[m];
prefix[0] = list.get(0);
for (int i = 1; i < m; i++) {
prefix[i] = prefix[i - 1] + list.get(i);
}
// Calculate distance for each index in the group
for (int i = 0; i < m; i++) {
int idx = list.get(i);
// Left part: idx * countLeft - sumLeft
long left = (long) idx * i - (i == 0 ? 0 : prefix[i - 1]);
// Right part: sumRight - idx * countRight
long right = (prefix[m - 1] - prefix[i]) - (long) idx * (m - i - 1);
res[idx] = left + right;
}
}
return res;
}
# python
# LC 2615 - Sum of Distances
# V0: HashMap + Prefix Sum
def distance(nums):
from collections import defaultdict
n = len(nums)
result = [0] * n
index_map = defaultdict(list)
# Group indices by value
for i, num in enumerate(nums):
index_map[num].append(i)
# Calculate distances for each group
for indices in index_map.values():
m = len(indices)
if m == 1:
continue
# Build prefix sum
prefix = [0] * m
prefix[0] = indices[0]
for i in range(1, m):
prefix[i] = prefix[i - 1] + indices[i]
total_sum = prefix[m - 1]
# Calculate distance using left-right split
for i in range(m):
idx = indices[i]
# Left: idx * countLeft - sumLeft
sum_left = prefix[i - 1] if i > 0 else 0
left_dist = idx * i - sum_left
# Right: sumRight - idx * countRight
sum_right = total_sum - prefix[i]
right_dist = sum_right - idx * (m - i - 1)
result[idx] = left_dist + right_dist
return result
Summary & Quick Reference
Complexity Quick Reference
| Operation | Time | Space | Notes |
|---|---|---|---|
| Build prefix sum array | O(n) | O(n) | One-time preprocessing |
| Range sum query | O(1) | O(1) | After preprocessing |
| Subarray sum with HashMap | O(n) | O(n) | Average case, O(n²) worst case |
| 2D prefix sum build | O(mn) | O(mn) | For m×n matrix |
| 2D range query | O(1) | O(1) | After preprocessing |
| Difference array updates | O(k) | O(n) | k updates, n array size |
Template Quick Reference
| Template | Pattern | Key Code Snippet |
|---|---|---|
| Template 1 | Basic Range Sum | prefix[i+1] = prefix[i] + nums[i] |
| Template 2 | HashMap + Target | if prefix_sum - k in map: count += map[prefix_sum - k] |
| Template 3 | Modulo/Divisibility | remainder = prefix_sum % k; if remainder in map... |
| Template 4 | Range Updates | diff[start] += val; diff[end+1] -= val |
| Template 5 | 2D Matrix | prefix[i][j] = val + left + top - topleft |
| Template 6 | Transform Count | transform array first, then apply prefix sum |
| Template 7 | Sum of Distances | left = idx * countLeft - sumLeft; right = sumRight - idx * countRight |
| Template 8 | Prefix Maximum | maxSoFar = max(maxSoFar, arr[i]); if (maxSoFar == i) chunks++ |
Core Mathematical Insights
Prefix Sum Formula
# For 1D array: sum of subarray [i, j] (inclusive)
subarray_sum = prefix[j + 1] - prefix[i]
# For 2D matrix: sum of rectangle from (r1,c1) to (r2,c2)
rectangle_sum = prefix[r2+1][c2+1] - prefix[r1][c2+1] - prefix[r2+1][c1] + prefix[r1][c1]
HashMap Key Insights
# If prefix_sum[j] - prefix_sum[i] = k
# Then prefix_sum[i] = prefix_sum[j] - k
# So check if (current_prefix_sum - k) exists in map
# For divisibility: if (sum[j] - sum[i]) % k = 0
# Then sum[j] % k = sum[i] % k
# So check if (current_sum % k) exists in remainder map
Common Patterns & Tricks
Pattern 1: Two Sum Extended
# Convert "find subarray with sum = k" to "find two prefix sums with diff = k"
def subarray_sum_equals_k(nums, k):
prefix_sum = 0
count = 0
prefix_map = {0: 1} # Critical: handle subarrays from index 0
for num in nums:
prefix_sum += num
count += prefix_map.get(prefix_sum - k, 0)
prefix_map[prefix_sum] = prefix_map.get(prefix_sum, 0) + 1
return count
Pattern 2: Difference Array Magic
# Apply multiple range updates [start, end, val] efficiently
def range_addition(length, updates):
diff = [0] * (length + 1) # Extra space for end+1 indexing
for start, end, val in updates:
diff[start] += val # Mark start
diff[end + 1] -= val # Mark end+1 (undo effect)
# Convert difference array to result using prefix sum
result = []
current = 0
for i in range(length):
current += diff[i] # This is prefix sum computation!
result.append(current)
return result
Pattern 3: Transform Before Sum
# Many problems can be reduced to simpler prefix sum problems
def count_nice_subarrays(nums, k):
# Transform: odd numbers → 1, even numbers → 0
# Problem becomes: count subarrays with sum = k
binary_array = [1 if x % 2 == 1 else 0 for x in nums]
return subarray_sum_equals_k(binary_array, k)
Problem-Solving Steps
-
Identify the Pattern
- Read problem carefully for keywords (range, subarray, sum, count, etc.)
- Check if multiple queries or single pass needed
- Look for mathematical relationships (divisibility, modulo, etc.)
-
Choose the Right Template
- Use decision flowchart to select appropriate template
- Consider time/space complexity requirements
- Check if transformation needed before applying prefix sum
-
Handle Edge Cases
- Empty arrays or single elements
- Negative numbers (especially for modulo operations)
- Integer overflow for large sums
- Zero values and their impact on divisibility
-
Optimize Implementation
- Initialize HashMap with base case (usually
{0: 1}) - Handle negative remainders in modulo operations
- Use one-pass algorithm when possible
- Consider space optimization if only counts needed
- Initialize HashMap with base case (usually
Common Mistakes & Tips
🚫 Common Mistakes:
- Forgetting base case: Not initializing HashMap with
{0: 1}for subarray problems - Off-by-one errors: Incorrect indexing in prefix sum arrays
- Negative remainders: Not handling
remainder < 0in modulo operations - HashMap timing: Adding to map before vs after checking condition
- 2D indexing: Confusing row/column indices in 2D prefix sum
- Range updates: Forgetting to subtract at
end+1in difference array
✅ Best Practices:
- Always initialize prefix sum arrays with size
n+1for 1-based indexing - Always add
{0: 1}to HashMap for subarray problems to handle edge cases - Double-check the order: check condition first, then update HashMap
- Handle negatives: Use
remainder = (remainder % k + k) % kfor modulo - Validate bounds: Check array bounds when using
end+1indexing - Test edge cases: Empty arrays, single elements, all negatives
Interview Tips
-
Pattern Recognition
- If you see “subarray sum equals K” → immediate HashMap + prefix sum
- If you see “range queries” → basic prefix sum array
- If you see “divisible by K” → modulo technique with HashMap
- If you see “multiple range updates” → difference array
-
Communication Strategy
- Explain the mathematical insight: “We’re looking for pairs of prefix sums”
- Draw examples showing how prefix sums work
- Mention time complexity improvement: “This reduces O(n²) to O(n)”
- Discuss space-time tradeoffs
-
Implementation Tips
- Start with brute force to verify understanding
- Then optimize using appropriate prefix sum template
- Explain why HashMap initialization matters
- Walk through a small example step by step
-
Follow-up Discussions
- Discuss variations: “What if we need maximum length instead of count?”
- Explain extension to 2D: “How would this work for matrices?”
- Consider constraints: “What if numbers are very large?” (overflow)
Related Topics
- HashMap/Hash Table: Essential for most advanced prefix sum problems
- Sliding Window: Can be combined with prefix sum for optimization
- Two Sum: Many prefix sum problems are extensions of two sum
- Dynamic Programming: Prefix sums often used as DP optimization
- Binary Search: Can be combined with prefix sum for range queries
- Segment Trees: Alternative for range sum with updates
- Monotonic Stack: Sometimes combined with prefix sum for optimization
Advanced Extensions
- Sparse Arrays: Use coordinate compression with prefix sum
- Online Queries: Segment trees or Fenwick trees for updates + queries
- 2D Range Updates: 2D difference arrays with 2D prefix sum
- Weighted Prefix Sum: Handle different weights for elements
- Circular Arrays: Modify templates to handle circular conditions
This comprehensive cheatsheet covers all major prefix sum patterns and provides systematic approaches for solving 40+ LeetCode problems efficiently.